I have tried to build a probability model of user's events using Markov process. It is a simple model to calculate the probability of the next events that would occur in the next time step, based on the historical data. It uses the Markov property in which the next state depends only on the current state and not on the sequence of events that preceded it. It assumes the current state has all information from all previous state. This model can generate some results, however I don't think it generates a great result in our problem scenario.
As the labels can be dependent, therefore calculating the next state might require the information of some previous states, not just the current state. For example, we have an event sequence for using Washing Machine (WM). I assume the current state is today, which the WM is used, and we want to calculate the chance that the user will use the WM tomorrow. By applying Markov property, to estimate the probability of using WM tomorrow, we only need the information of the current state, which is the probability of using WM today. This probability is calculated from the historical data.
In a real scenario, using WM at the next state can be dependent on some previous use of WM in the past. Therefore, using Markov process in our model will not give a good result in prediction. However, we can use the model with Markov property as a bench mark to compare with other models, which I will research and implement.
I have read a paper of "A Model for Temporal Dependencies in Event Streams". They try to solve a very similar problem that I am trying to solve. They introduce the Piecewise-Constant Conditional Intensity Model (PCIM) to model the types and timing of events and capture the dependencies of each type of event on events in the past through a set of piecewise-constant conditional intensity functions. The model is very complicated, but I want to implement this model to FigureEnergy data. They apply Bayesian Network Learning in their model, so I will try to read and understand this area more.
Thursday, 15 December 2011
Tuesday, 13 December 2011
Mathematical model for event prediction
Predicting user's activities is not an easy task. Specifically, the activities themselves are dependent to each other, and the information of activities are given in uncertain ways (i.e., it is hard to get fully correct information of events in reality).
Previously, I have tried Poisson processes to predict user's events, however it has been uncesseful model as the events are independents in Poisson process. Continuing researching for an appropirate model, I have had a good chat with Long about a model, still using Markov process. I think we came with an appealing model, which also works for dependent data. I am implementing the model with the data collected from the FigureEnergy system, however there is not enough information to conclude this model. For further testing, I will test it with a large appropriate data, which are released by MIT. Thanksfully the data can be obtained from Oli. I will try to implement this model asap for further analysis.
Then, I will have to define a scenario in a formal mathematical way, then an existing model will be chosen to implement as a benchmark for future comparison. In addition, the paper of "A model for Temporal Dependencies in Event Streams" will be needed to read and understand as well.
Previously, I have tried Poisson processes to predict user's events, however it has been uncesseful model as the events are independents in Poisson process. Continuing researching for an appropirate model, I have had a good chat with Long about a model, still using Markov process. I think we came with an appealing model, which also works for dependent data. I am implementing the model with the data collected from the FigureEnergy system, however there is not enough information to conclude this model. For further testing, I will test it with a large appropriate data, which are released by MIT. Thanksfully the data can be obtained from Oli. I will try to implement this model asap for further analysis.
Then, I will have to define a scenario in a formal mathematical way, then an existing model will be chosen to implement as a benchmark for future comparison. In addition, the paper of "A model for Temporal Dependencies in Event Streams" will be needed to read and understand as well.
Thursday, 8 December 2011
A quick update of my work.
In the last meeting, we discovered that the Poisson process is not a good model to apply in our scenario. It considers events are independent, while they are dependent in our case. Therefore, I need to switch to another appealing model, which should be done before 01 January 2012.
The strategy is to looking for models which work with dependent data. In addition, I need to gain much knowledge about machine learning and other mathematical models, so I am able to judge and select the right one.
I kick off with the paper of "Unsupervised Disaggregation of Low Frequency Power Measurements", which has been given by Oli. The paper mainly discusses the effectiveness of several unsupervised disaggregation methods using the factorial hidden Markov model on low frequency power measurements collected in real homes. In their model, the states of appliances are the hidden variables, and the aggregate power load is the observation. Therefore, they chose variants of Hidden Markov Model (HMM). More specially, they extend a Conditional Factorial Hidden Semi-Markov Model (CFHSMM), which allows the model to consider the dependencies between appliances and the dependencies on additional features, that I think is quite relevant to our case. Then, they apply machine learning process to estimate the parameters from the observations, and the hidden variables (which is the states of the appliances). Specifically, they use Expectation-Maximization algorithm (EM) to estimate the parameters, then using Maximum Likelihood Estimation (MLE) to estimate the hidden states.
In our case, the events are possibly annotated by users. So, I think Hidden Semi-Markov models could be used. I will check more references paper on CFHSMM to see if there is any relevant existing models.
Furthermore, I have grasped some book to read with the hope to have a better overal view on machine learning models. I will check out this list:
- Chapter 9: Mixture Models and EM (423-455) (book " Pattern Recognition and Machine Learning" - Christopher M. Bishop).
- Chapter 6: Bayesian Learning (154-199) (book: "Machine Learning" - Tom M. Mitchell).
The strategy is to looking for models which work with dependent data. In addition, I need to gain much knowledge about machine learning and other mathematical models, so I am able to judge and select the right one.
I kick off with the paper of "Unsupervised Disaggregation of Low Frequency Power Measurements", which has been given by Oli. The paper mainly discusses the effectiveness of several unsupervised disaggregation methods using the factorial hidden Markov model on low frequency power measurements collected in real homes. In their model, the states of appliances are the hidden variables, and the aggregate power load is the observation. Therefore, they chose variants of Hidden Markov Model (HMM). More specially, they extend a Conditional Factorial Hidden Semi-Markov Model (CFHSMM), which allows the model to consider the dependencies between appliances and the dependencies on additional features, that I think is quite relevant to our case. Then, they apply machine learning process to estimate the parameters from the observations, and the hidden variables (which is the states of the appliances). Specifically, they use Expectation-Maximization algorithm (EM) to estimate the parameters, then using Maximum Likelihood Estimation (MLE) to estimate the hidden states.
In our case, the events are possibly annotated by users. So, I think Hidden Semi-Markov models could be used. I will check more references paper on CFHSMM to see if there is any relevant existing models.
Furthermore, I have grasped some book to read with the hope to have a better overal view on machine learning models. I will check out this list:
- Chapter 9: Mixture Models and EM (423-455) (book " Pattern Recognition and Machine Learning" - Christopher M. Bishop).
- Chapter 6: Bayesian Learning (154-199) (book: "Machine Learning" - Tom M. Mitchell).
Thursday, 1 December 2011
Poisson Process prediction vs the actual data
In this post, I do some comparison between the actual events that used by the given user, and the predictive events using by PPs. I firstly take 14 training days to calculate the mean number of event types. From the given event file, there is only user ecenergy39 that has the maximum historical data of 17 days, therefore I only use this user to generate the results.
 As you can see from the above graph, by using 14 days as a training period, TV and Kettle are predicted to occur in the next 24 hours with the probability very high, approximately 80%. The actual results show that TV event has been annotated for 4 times, while "kettle" event has been annotated for 1 times.
As you can see from the above graph, by using 14 days as a training period, TV and Kettle are predicted to occur in the next 24 hours with the probability very high, approximately 80%. The actual results show that TV event has been annotated for 4 times, while "kettle" event has been annotated for 1 times.
Then, we use 15 days as a training period to predict the events occured in the next 24 hours. The result is below:
 The process is repeated for the 17th day, with the result as follows:
The process is repeated for the 17th day, with the result as follows:

As we all know that the data of events are collected from the real experiment, where users manually annotated the information of the event. Therefore, the data itself has so much noise. We need to think of the solution of increase the accuracy of the event information. The direction could be automatically recognise the pattern of the events.

Then, we use 15 days as a training period to predict the events occured in the next 24 hours. The result is below:


As we all know that the data of events are collected from the real experiment, where users manually annotated the information of the event. Therefore, the data itself has so much noise. We need to think of the solution of increase the accuracy of the event information. The direction could be automatically recognise the pattern of the events.
User's Average Day Calculation (with more user's data)
I have been given more user's data of energy consumption, therefore I plotted again the average day for some specific users between the weekdays and weekend days. The following graphs show some results:







 With more data, the gap of energy consumed between the weekdays and the weekend days has become maller, and look regularly.
With more data, the gap of energy consumed between the weekdays and the weekend days has become maller, and look regularly.








Tuesday, 29 November 2011
Apply Poisson process on FE labels
A Poisson process (PPs) is a collection {N(t), t>=0} of random variables, where N(t) is the number of events that have occured up to time t (starting from time 0). By using PPs, we can calculate the probablity of actual number of events that would be occured in the given period.
In our scenario, we have a list of the data of the events, which annotated by users using the FigureEnergy system. We want to use PPs to calculate the probability that event will be occured in the next time period (typically in daily unit). If the probability of the event to be occured is high (greater than 70%), we can ask the users to confirm the information. Then, we will be able to run the optimisation problem of minimising the carbon intensity, then we can send feedback to users by advising them using the events in the appropriate time.
To do that, firstly we filter all labels of the specific user. Then, we calculate the mean number of events per day. After that, we use PPs to calculate the probability of no labels which would be occureed in the next 24 hours. The results of the few users can be seen as follows:


 From the graph above, we can tell the events that will be like occured in the next 24 hours. For example, for user "ecenergy39", the probability of using TV and Kettle in the next 24 hours are very high (greater than 80%).
From the graph above, we can tell the events that will be like occured in the next 24 hours. For example, for user "ecenergy39", the probability of using TV and Kettle in the next 24 hours are very high (greater than 80%).
Next step, I will check the accurate of the PPs prediction on the real FE data.
In our scenario, we have a list of the data of the events, which annotated by users using the FigureEnergy system. We want to use PPs to calculate the probability that event will be occured in the next time period (typically in daily unit). If the probability of the event to be occured is high (greater than 70%), we can ask the users to confirm the information. Then, we will be able to run the optimisation problem of minimising the carbon intensity, then we can send feedback to users by advising them using the events in the appropriate time.
To do that, firstly we filter all labels of the specific user. Then, we calculate the mean number of events per day. After that, we use PPs to calculate the probability of no labels which would be occureed in the next 24 hours. The results of the few users can be seen as follows:



Next step, I will check the accurate of the PPs prediction on the real FE data.
Meeting on 25 November 2011.
Pre-meeting notes on 25 Nov 2011.
1 – Tasks have been tackled:
· Calculated and plotted user consumption in average day again in week days and weekend days. Different users show a different result. Interestingly, there is a correlation of consuming energy between the weekday and weekend days for the same user in average day.
· Plotted frequency of labels per day for both single users and all users.
· Have done some reaching on Google scholar about event prediction and faults in machinery. I think I have obtained some nice papers but have not read them all.
· Have read about Poisson process in the wiki. In addition, I have researched more tutorials and sections talking about Poisson process. I have gone through some examples and have understood some basic principles to apply to our case. Furthermore, I have prepared some calculation in draft to calculate the probability of events to appear at the given time step t. However, I have not yet successfully implemented in Matlab to generate the graph.
· Have chatted with Rama about the problem that I am trying to tackle. I found it is hard to describe the issue in email, therefore I talked to him instead. The talk was just around events prediction and how to improve the event information as well as the prediction. He suggested some nice things, I summarise a few key things as follows:
· As each event has its own energy usage. By using FE, the user annotates the event from the past history. By using this way, the information given from the user would have so much noise, and it is hard to tell the exact amount of energy that event would consume. Therefore, we should have a method to improve the certainty of event information. At the time being, I just assume that the events in FE would show the right information, including the time period and the usage of events.
· Having predicted the events for a day ahead (I suppose this could be done by using Poisson process), how the agent system can improve the event prediction.
· The optimisation of machine learning will focus on minimise both aggregate demand and events time.
· Attended the probability course, which has been started intensively for 2 weeks.
2 – Remaining tasks:
· Detect events based on peaks.
· Read 1-2 related papers
· Find existing work or models to apply to our situation.
· Prepare emails to Steve Reece. (Not sure what I should say in here)
After meeting discussion:
3 – Next tasks:
· Look, understand and implement Poisson distribution. Particularly, understand likelihood, Bayesian inference and confidence interval.
· During the meeting, I and Enrico have a discussion about making a prediction of the specific event at the specific time. In my opinion, I think if we can predict the event at the specific time, then we can have an optimisation problem by minimising the carbon intensity based on scheduling the events. After that, this scheduling will be suggested to users. However, it could be impossible to correctly predict the events at the given time as they are controlled by the real human.
An alternative option is to predict the event to be happened in the next 24 hours, then we could make a suggestion to users to run the event at the other time to minimise the carbon intensity. The event with the probability is higher than 80% will be selected to suggest to users. Furthermore, we can calculate the difference between the worst case and the best case to advise users more effectively. However, how to run the optimisation without knowing the time, I am still not clear.
Thursday, 24 November 2011
Frequency of labels for all users
I attended a probability lecture today. This probability course would be supposed to cover a whole range of anything related to distribution. Hence, the material is useful, but it is hard to follow.
Back to FigureEnergy data analysis, I plotted the frequency of labels per day for all users. The result is showed in Figure 1.0 as follows:
I think Poison process can help to estimate the labels in the future based on the frequency of the appearances of labels. The annotated events data in FE seems so much noise, therefore we need to define a method the automatically recognise the events.
In addition, I will try to implement Poison process on the energy consumption, where the energy usages can be divided into smallers segments of energy usage. By using Poison process, I hope it can tell the highest probability of particular segment of energy usage for the given time.
Back to FigureEnergy data analysis, I plotted the frequency of labels per day for all users. The result is showed in Figure 1.0 as follows:
 |
| Figure 1.0 Frequency of labels appearances per day for all Users |
In addition, I will try to implement Poison process on the energy consumption, where the energy usages can be divided into smallers segments of energy usage. By using Poison process, I hope it can tell the highest probability of particular segment of energy usage for the given time.
Tuesday, 22 November 2011
Frequency of events analysis
Different users have a list of their own activities during a day. These activities might have a chance to regconise as a pattern. To analyse this, we take the events which annotated from the real users during the FigureEnergy experiment to check the frequency of the type of events per day in term of appearance and energy usage. The results are shown as follows:
 |
| Figure 1. Frequency of events for user ecenergy22 |
 |
| Figure 2. Frequency of events for user ecenergy23 |
 |
| Figure 3. Frequency of events for user ecenergy24 |
 |
| Figure 4. Frequency of events for user ecenergy25 |
 |
| Figure 5. Frequency of events for user ecenergy30 |
 |
| Figure 6. Frequency of events for user ecenergy33 |
 |
| Figure 7. Frequency of events for user ecenergy34 |
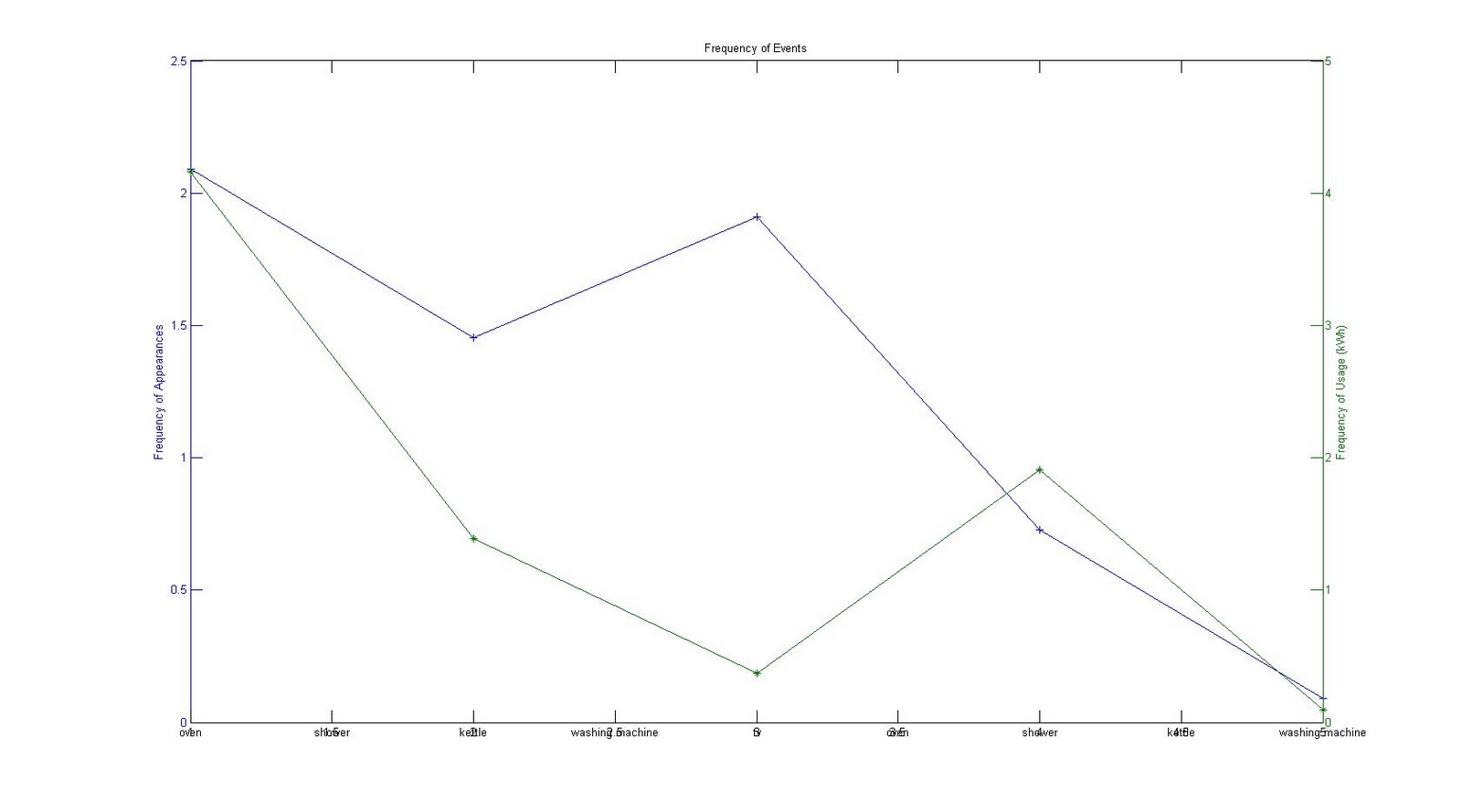 |
| Figure 8. Frequency of events for user ecenergy36 |
"Average Day" data again in weekday and weekend
I have plotted the "average day" usage again in weekday and weekend days from several users. The results are shown as follows:
The graph for those users above could be different if their usage data can be collected in at least 4 weeks.
 |
| Figure 1. Average day usage for user ecenergy22 |
 |
| Figure 2. Average day usage for user ecenergy23 |
 |
| Figure 3. Average day usage for user ecenergy25 |
 |
| Figure 4. Average day usage for user ecenergy30 |
 |
| Figure 5. Average day usage for user ecenergy32 |
 |
| Figure 6. Average day usage for user ecenergy33 |
 |
| Figure 7. Average day usage for user ecenergy34 |
 |
| Figure 8. Average day usage for user ecenergy35 |
 |
| Figure 9. Average day usage for user ecenergy36 |
 |
| Figure 10. Average day usage for user ecenergy37 |
 |
| Figure 11. Average day usage for user ecenergy38 |
 |
| Figure 12. Average day usage for user ecenergy39 |
Friday, 18 November 2011
Meeting notes on 18/11/2011 (Revised version)
1 – List of Tasks from previous meeting:
· Post a research plan in blog.
2 – Discussion:
· Post a research plan in blog.
· Plot user consumption hourly for some specific days.
· Plot average day on different users.
I have done all the previous tasks. Each individual user has a different profile of energy usage in “average day”. We might guess the energy behaviour and user’s lifestyle based on looking on these graphs.
· Calculate and plot user consumption in “average day” again in week days and weekend days.
· Plot frequency (on all labels) per day. Look further into the idea of detect the peak usage, from different thresholds.
· Look further into detect events, based on peaks. Check the different signal, where y(t) = x(t) – x(t-1), where 1 is a time unit (currently time unit is 2 mins in FigureEnergy). Check to see if “low pass frequency” can apply anywhere in this part. Be aware of two types of statistics: user annotation, and peaks (e.g., washing machine has 2 peaks).
· Research on Google scholar for “event prediction Gaussian”, predicting faults in machinery, and predicting “network traffic” and post what you would have found.
· Look at “Poison process” in the wiki, check the relevant papers.
· Read and summarise 1-2 papers weekly.
· Try to find existing works in a different domain and translate those models to our situation, typically 2-3 existing models.
· Look and report on research where agents to keep calendars and agents to book rooms. (probably from http://teamcore.usc.edu/)
· Prepare an email to ask agent’s research fellow (Sid, Rama, Greg) to ask about their suggestion on the relevant mathematical model that I should use.
· Prepare an email and a dataset (in .csv format) to send to Steve Reece about how to proceed with the prediction.
· Improve English (I have attended the Academic Writing English course (1 hour/week, in 6 weeks), however I found it would not help much in my situation. It showed some principle of how to make a good writing structure and talk a bit about everything, but it is not enough for me. I think I might look for a paid tutor to improve this weakness. At the time being, I will try to revise my blog and might get someone to check the writing. I might need to read at Oli’s blog to learn the informal writing style as well).
· Optional:
· Register course in probability
· Register online course in Machine Learning (web-seminar from Stanford University)
· Read paper: “A decision-Theoretic Approach to Cooperative Control and Adjustable Autonomy”
Pre-meeting notes on 18/11/2011.
1 – List of Tasks from previous meeting:
· Post a research plan in blog.
· Plot user consumption hourly for some specific days.
· Plot average day on different users.
2 – Discussion:
I have done all the previous tasks. Each individual user has a different profile of energy usage in “average day”. We might guess the energy behaviour and user’s lifestyle based on looking on these graphs.
3 – List of next tasks (sorted in order of priority)
· Calculate and plot user consumption in “average day” again in week days and weekend days.
· Research on Google scholar for “event prediction Gaussian”, “predicting faults in machinery”, and predicting “network traffic” and post what you would have found.
· Try to find existing works in a different domain and translate those models to our situation, typically 2-3 existing models.
· Look and report on research where agents to keep calendars and agents to book rooms.
· Look for the existing infrastructure on Google calendar, ICS format.
· Prepare an email and a dataset (in .csv format) to send to Steve Reece about how to preceed with the prediction.
· Improve English (I have attended the Academic Writing English course (1 hour/week, in 6 weeks), however I found it would not help much in my situation. It showed some principle of how to make a good writing structure and talk a bit about everything. I think I might look for a paid tutor to improve this weakness).
· Look into frequency in term of user-generated events, the basis of power level, or the time it takes between two instant where power goes above x.
· Optional:
· Register course in probability
· Register online course in Machine Learning (web-seminar from Stanford University)
· Read paper: “A decision-Theoretic Approach to Cooperative Control and Adjustable Autonomy”
"Average Day" data plotting.
I have plotted an energy consumption of "average day" for different users. The results will be shown as follow:
 |
| Figure 1.0 - Average Day consumption for User ecenergy22 in 14 days |
 |
| Figure 2.0 - Average Day consumption for User ecenergy23 in 11 days |
 |
| Figure 3.0 - Average Day consumption for User ecenergy24 in 10 days |
 |
| Figure 4.0 - Average Day consumption for User ecenergy25 in 7 days |
 |
| Figure 5.0 - Average Day consumption for User ecenergy30 in 7 days |
 |
| Figure 6.0 - Average Day consumption for User ecenergy32 in 18 days |
 |
| Figure 7.0 - Average Day consumption for User ecenergy33 in 17 days |
 |
| Figure 8.0 - Average Day consumption for User ecenergy34 in 11 days |
 |
| Figure 9.0 - Average Day consumption for User ecenergy35 in 11 days |
 |
| Figure 10.0 - Average Day consumption for User ecenergy36 in 12 days |
Friday, 11 November 2011
Hourly consumption analysis
I have calculated an energy of user consumption in every hour to see if we can observe any patern, which could help to improve the prediction. I firstly run a whole data of user ecenergy22. The result can be seen in Figure 1.0 below:
Then, I generate the results in the first 13 days for an ease of observation. The following figures shows the daily user consumption in every hour unit.
 |
| Figure 1.0 User consumption in every hour. |
Then, I generate the results in the first 13 days for an ease of observation. The following figures shows the daily user consumption in every hour unit.
 |
| Figure 2.1 User consumption on 06/09/2011. |
 |
| Figure 2.2 User consumption on 07/09/2011. |
 |
| Figure 2.3 User consumption on 08/09/2011. |
 |
| Figure 2.4 User consumption on 09/09/2011. |
 |
| Figure 2.5 User consumption on 10/09/2011. |
 |
| Figure 2.6 User consumption on 11/09/2011 |
 |
| Figure 2.7 User consumption on 12/09/2011. |
Subscribe to:
Posts (Atom)