Pre-meeting notes on 25 Nov 2011.
1 – Tasks have been tackled:
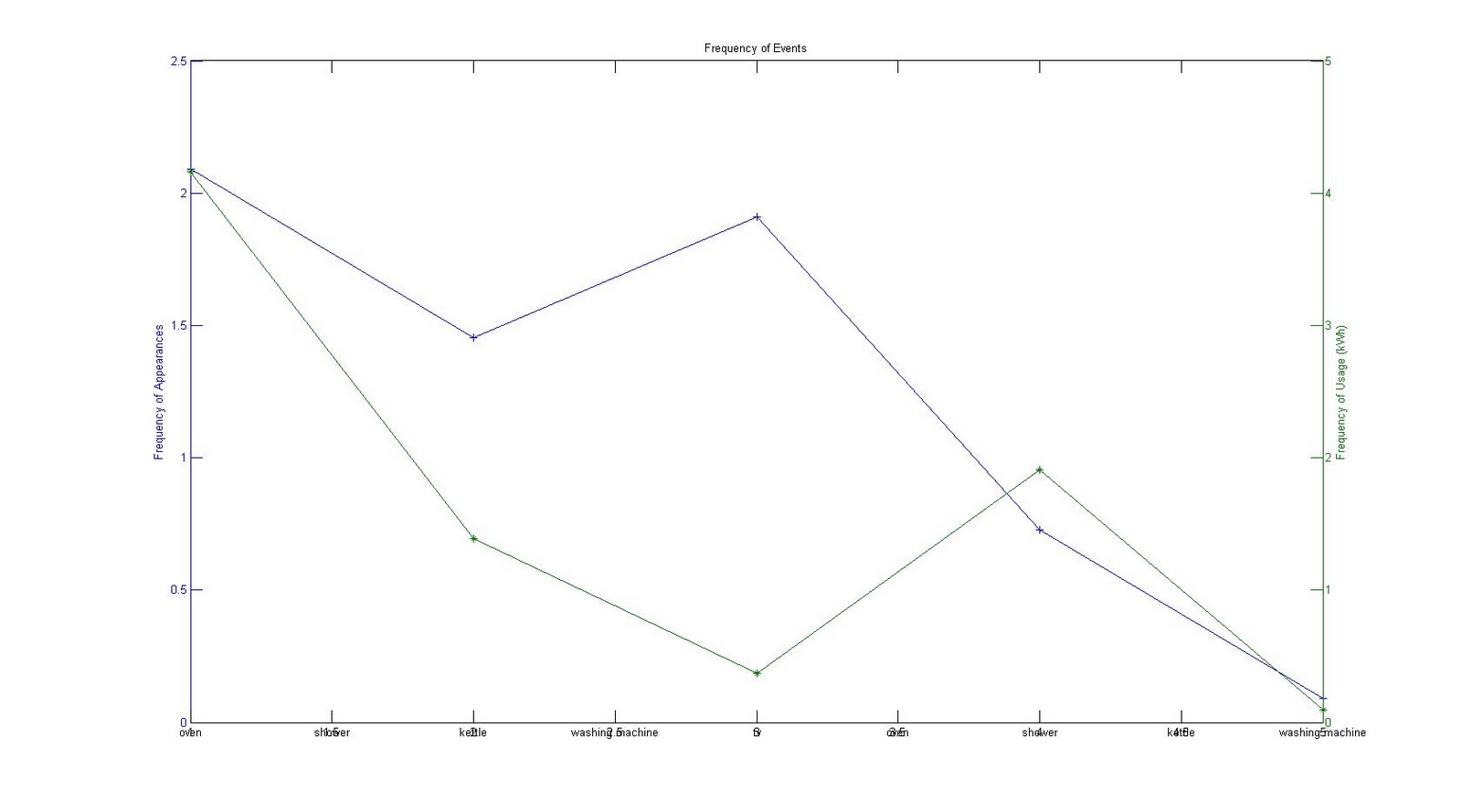
· Calculated and plotted user consumption in average day again in week days and weekend days. Different users show a different result. Interestingly, there is a correlation of consuming energy between the weekday and weekend days for the same user in average day.
· Plotted frequency of labels per day for both single users and all users.
· Have done some reaching on Google scholar about event prediction and faults in machinery. I think I have obtained some nice papers but have not read them all.
· Have read about Poisson process in the wiki. In addition, I have researched more tutorials and sections talking about Poisson process. I have gone through some examples and have understood some basic principles to apply to our case. Furthermore, I have prepared some calculation in draft to calculate the probability of events to appear at the given time step t. However, I have not yet successfully implemented in Matlab to generate the graph.
· Have chatted with Rama about the problem that I am trying to tackle. I found it is hard to describe the issue in email, therefore I talked to him instead. The talk was just around events prediction and how to improve the event information as well as the prediction. He suggested some nice things, I summarise a few key things as follows:
· As each event has its own energy usage. By using FE, the user annotates the event from the past history. By using this way, the information given from the user would have so much noise, and it is hard to tell the exact amount of energy that event would consume. Therefore, we should have a method to improve the certainty of event information. At the time being, I just assume that the events in FE would show the right information, including the time period and the usage of events.
· Having predicted the events for a day ahead (I suppose this could be done by using Poisson process), how the agent system can improve the event prediction.
· The optimisation of machine learning will focus on minimise both aggregate demand and events time.
· Attended the probability course, which has been started intensively for 2 weeks.
2 – Remaining tasks:
· Detect events based on peaks.
· Read 1-2 related papers
· Find existing work or models to apply to our situation.
· Prepare emails to Steve Reece. (Not sure what I should say in here)
After meeting discussion:
3 – Next tasks:
· Look, understand and implement Poisson distribution. Particularly, understand likelihood, Bayesian inference and confidence interval.
· During the meeting, I and Enrico have a discussion about making a prediction of the specific event at the specific time. In my opinion, I think if we can predict the event at the specific time, then we can have an optimisation problem by minimising the carbon intensity based on scheduling the events. After that, this scheduling will be suggested to users. However, it could be impossible to correctly predict the events at the given time as they are controlled by the real human.
An alternative option is to predict the event to be happened in the next 24 hours, then we could make a suggestion to users to run the event at the other time to minimise the carbon intensity. The event with the probability is higher than 80% will be selected to suggest to users. Furthermore, we can calculate the difference between the worst case and the best case to advise users more effectively. However, how to run the optimisation without knowing the time, I am still not clear.